
Mark Twain Project Online Technical Summary
- Introduction
- How to Use This Document
- System Overview
- Content Sources
- Content Transformation and Transfer
- User Experience and Technical Implementation
I. Introduction
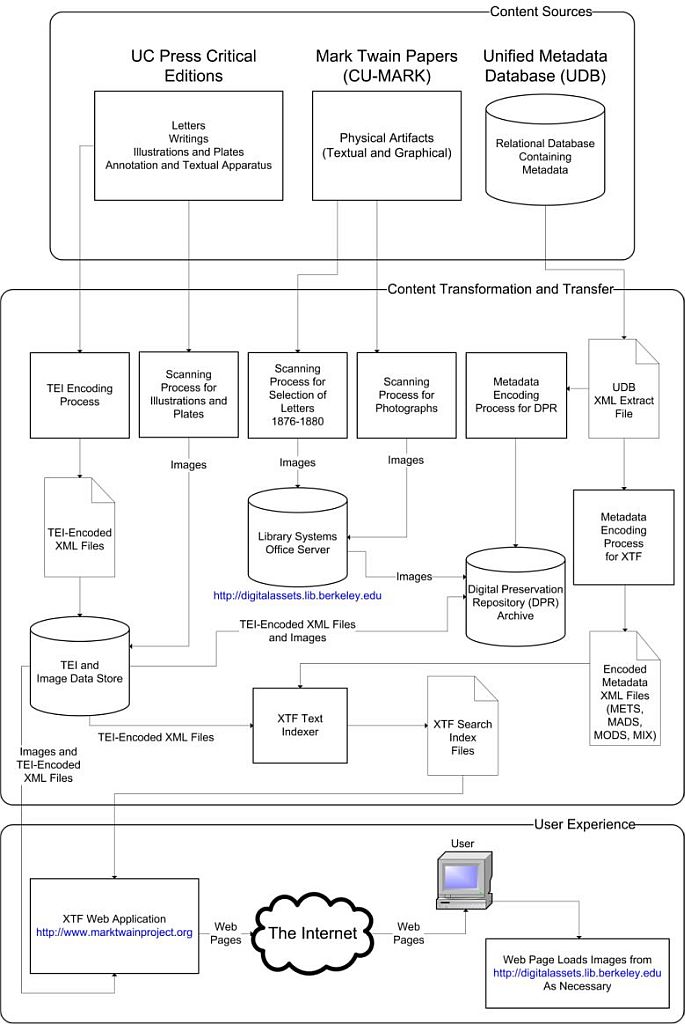
This document, written in 2007 and last updated in 2016, describes the technical architecture of the Mark Twain Project Online (MTPO). It is organized into sections representing each component of the system. The components are ordered within the document according to their location in the system data flow, as illustrated in Figure 1.
The MTPO website is accessible at http://www.marktwainproject.org/.
II. How to Use This Document
Readers should use the document as an overview of the system and not as a detailed technical guide. For more information about a specific technology or component, click on the related links located throughout the document.
III. System Overview
MTPO is a web application and content publishing system. Content is stored in a relational database and in electronic flat files. These content collections include the texts of various literary works and letters with their editorially supplied textual apparatus, as well as digitized photographs, document facsimiles, and metadata. Metadata also exist for many documents and images not available to MTPO, such as those held at other institutions. The content is published to a web application that provides content search and display functionality. Figure 1 provides a system overview of MTPO.
Figure 1
IV. Content Sources
In order to manage the scope of this document, content sources are defined as systems that directly feed the transformative processes. For example, a plate in a critical edition may have come from a scanned image that was created by an institution other than the University of California (UC) Press or the Mark Twain Project. Such institutions are not defined as content sources of MTPO, however, because they are twice removed from any of the transformative processes.
UC Press Critical Editions
Printed critical editions, produced by the Mark Twain Project since 1967, were conceived prior to MTPO's launch as the primary source of content for MTPO. These volumes have originated as WordPerfect documents since the mid-1980s, and many have existed since 2004–5 as TEI-XML documents. The initial release of MTPO included the following content:
1. Mark Twain's Letters, 1853–1875: six volumes, published 1988–2002
2.
Mark Twain's Letters, 1876–1880, including scans of locally owned manuscripts
Subsequent releases have been described and linked on MTPO's Recent Changes page as well as relevant landing pages.
Working files for the Mark Twain Project's editions are stored on a secure server owned and managed by The Bancroft Library.
Mark Twain Papers (CU-MARK)
The Mark Twain Papers (CU-MARK) is the largest archive of original documents written by and about Mark Twain. These include letters to and from Mark Twain as well as manuscripts and other important collateral documents. In addition to its collection of textual artifacts, CU-MARK maintains a collection of photographic artifacts portraying Mark Twain and related subjects.
Unified Metadata Database (UDB)
The Unified Metadata Database (UDB) is a FRBRized data model describing MTPO content, which is housed in a Microsoft Access relational database in the first phase of the project. Care was taken to base the data model on metadata and biographical information digital library standards, namely Metadata Encoding and Transmission Standard (METS), Metadata Authority Description Schema (MADS), Metadata Object Description Schema (MODS) and NISO Metadata for Images in XML Schema (MIX). The database serves both as a content management system for the Mark Twain Project and as a repository from which METS submission packages can be generated for use by the XTF indexing service. It contains the consolidated metadata for all SLC works available in the Writings catalog, and related physical and digital entities accessible on the MTPO website as well as some objects inaccessible through MTPO. The UDB was populated from nine legacy Microsoft Access databases which underwent normalization: metadata was enriched from TEI sources, and system data was added to make the system relational.
In addition to storing metadata describing works and their manifestations, the system stores related authority metadata for creator, subject, and bibliographical entries, which it outputs as MADS records. As a content management system the UDB also tracks changes to metadata and data objects.
V. Content Transformation and Transfer
In order to deliver the critical editions along with related descriptive and authority information over the Internet, the system must extract the “raw” content from its respective content stores and transform it into a format that fulfills the required user experience. This section describes those reformatting processes and the means by which the data are transferred between systems—in other words, the “publishing” process wherein physical artifacts and data entry are published to the MTPO website.
TEI Encoding
The Text Encoding Initiative (TEI), an XML-based text encoding standard, is used by MTPO to structure the critical edition text. The encoding process is accomplished by manually transcribing print critical editions into TEI-XML documents. One of the challenges engendered by this process is limiting the rate of manual data-entry errors effectively. Maintaining a low error rate is achieved through a set of clear, detailed, and comprehensive encoding guidelines. These guidelines provide step-by-step instructions for encoding complicated sections of the text, such as the textual apparatus. The guidelines also specify validation procedures to be performed by the encoder after transcription. The documents are proofread as a final check against errors.
MTPO's P4 schema extends the TEI P4 DTD via two files,
MTDPext.dtd and MTDPext.ent; its P5 schema extends TEI
P5 via mtp4.xml, which records customizations made with TEI's Roma
tool. Most of the modifications either define additional attributes, allowing a text's structure to be described in
greater detail, or enable one element to be nested within another. Without these customizations, MTPO's encoding needs
and advanced user experience requirements could not be met.
Example 1a shows how MTDPext.dtd specifies the P4 <note> element with the @type
attribute. Example 1b shows part of the corresponding specification in P5.
Example 1a
<!ATTLIST note id ID #IMPLIED corresp IDREF #IMPLIED n CDATA #IMPLIED place ( end | foot | inline ) #IMPLIED rend CDATA #IMPLIED resp CDATA #IMPLIED lang CDATA #IMPLIED hand IDREF %INHERITED; target CDATA #IMPLIED targetEnd CDATA #IMPLIED type (alt | an | au | cp | ed | label | pt | te) #IMPLIED xml:space (default|preserve) 'default' >
Example 1b
<attribute name="type">
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0">characterizes
the element in some sense, using any convenient classification scheme or
typology.</a:documentation>
<choice>
<value>alt</value>
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0"/>
<value>an</value>
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0"/>
<value>au</value>
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0"/>
<value>cp</value>
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0"/>
<value>ed</value>
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0"/>
<value>label</value>
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0"/>
<value>mwn</value>
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0"/>
<value>pt</value>
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0"/>
<value>te</value>
<a:documentation xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0"/>
</choice>
</attribute>
Each @type attribute value indicates a different kind of note. For example, the value
“an” denotes an annotation. The value “ed” indicates that the note is an
editorial remark. To display a note online in a way appropriate to that type of note, the value of the @type
attribute is interrogated by the web application and used to make a formatting decision.
In addition to structuring the text in TEI-compliant form, MTPO specifies certain glyphs using the Unicode standard (UTF-8).
This policy facilitates the accurate display of text on platforms and web browsers whose default setting is not U.S. English.
For example, the left double quotation mark (“) is encoded in MTPO's documents as “.
When MTPO was first launched, Unicode 4.0 was the current version, and few web-optimized fonts included the full set of
specialized glyphs used in MTPO's editions. To resolve this issue, custom images were created to represent the glyphs.
For example, a white diamond (Unicode: ◇) denotes a character, numeral, or punctuation mark damaged
beyond legibility in a manuscript. Within MTPO, an image in GIF format was used in place of the Unicode code point value
◇, and @alt text identifies the image's content. Figure 2 shows the white diamond
glyph.
Figure 2

In 2015, glyph representation and font support of Unicode 8.0 were re-evaluated, and many (not all) of the custom images were retired.
Each letter document in the critical edition is encoded in a separate file. Encoding letters as separate files rather than bundling all of them in a single file eases implementation of the functionality for searching and displaying individual letters, which is the desired user experience. Literary works to date have been encoded as one inclusive file even when the work contains several logical sections, as in the case of Huck Finn and Tom Sawyer among the Indians, and Other Unfinished Stories.
Other modifications made during the TEI encoding process include assigning unique biographical IDs to letter writers and
addressees, so that they may be cross-referenced against an authority file, and adding hyperlinks to cross-references within
documents. Each TEI document features a full <teiHeader>, including a source description
(<sourceDesc>), which records copy-text information for letter documents and, for previously printed
material, provides a full bibliographic record of the print source.
The TEI encoding process for letters previously published in print is shown in Figure 3.
Figure 3
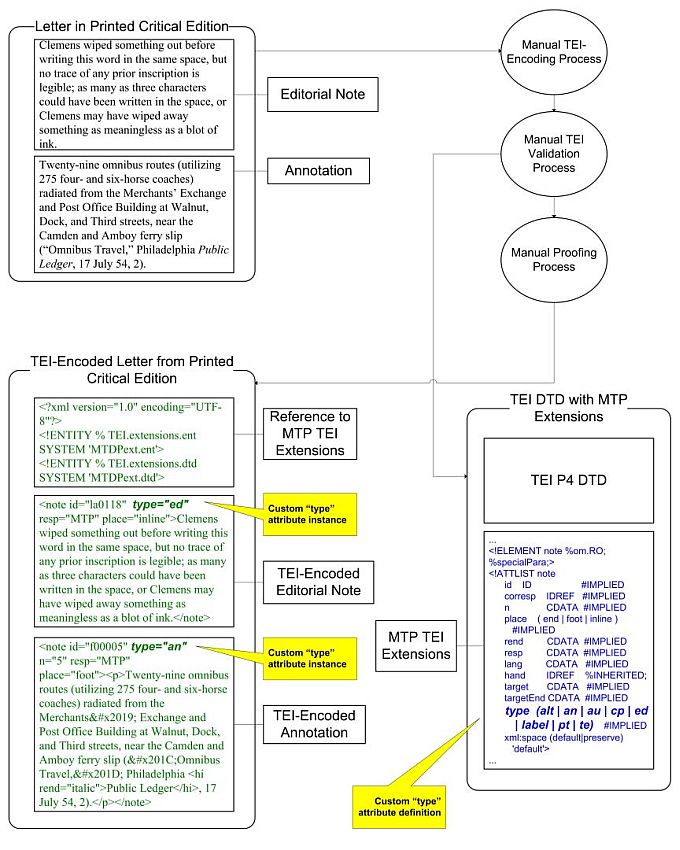
Image Scanning and Transfer
Two image sets are currently available online. One set comprises facsimile scans of letters written by Mark Twain between 1876 and 1880 and held at CU-MARK. The images were created in 1999 by the Digital Imaging Lab (DIL) at the University of California, Berkeley, and are served directly from a Library Systems Office (LSO) server at UC Berkeley.
The second part of the image set consists of scans from the extensive photograph collection held by CU-MARK.
Metadata Encoding
MTPO uses digital library standards to encode metadata. The process of metadata encoding begins with the extraction of metadata from the UDB into an XML file. The XML file is structured to conform to the Microsoft Office XML schema for data extraction, which is the default schema used for exporting data in XML format from Microsoft Access. The XML export is processed by a number of XSLT scripts that transform it into METS objects—wrapping the descriptive metadata in Metadata Object Description Schema (MODS), the technical metadata for images in NISO Metadata for Images in XML Schema (MIX), and the authority data in Metadata Authority Description Schema (MADS).
The encoding program is a script written in the Perl programming language. The Perl script, in turn, invokes Saxon, an XSL transformation program written in Java. The encoding program runs as a scheduled process.
Indexing for Search
To enable the discovery of digital objects through search on the MTPO site, a search index must be created from the objects and their related metadata. MTPO uses the eXtensible Text Framework (XTF) software to build its search index.
XTF is a text search and display software package written in Java which relies heavily on XML and XSLT. The software was designed by California Digital Library (CDL) engineers and is available for download as an open-source project on the CDL website. The software provides a tool called the Text Indexer, which builds search indices from disparate types of data.
The Text Indexer is invoked from the operating system command line using a small startup script written in Perl. The core of the Text Indexer is based on Lucene, an open-source text search engine written in Java and maintained by the Apache Software Foundation. The Text Indexer can be configured to index files in XML, PDF, HTML, and plain text. It can also be configured to augment XML documents with data stored in a Java Database Connectivity (JDBC) compliant database. Once the Text Indexer is installed and configured, it can be run against all the files in a given file system location or a subset of those files. The Text Indexer transforms the input data into a search-optimized set of output files that comprise the search index. The transformation involves converting the input data that is not already in XML format into XML and applying a configurable XSL style sheet, called the preFilter, to the data, which allows search results to be customized to the needs of the search provider. The resulting XML is transformed into small chunks which are then processed by the Lucene search engine. The Text Indexer is also capable of creating a search index by processing only the changes made to the input data since the last indexing was run. This functionality, called incremental indexing, allows input data changes to be reflected quickly in the search index without having to re-index the full data set.
An important feature of the Text Indexer is its ability to enable the “faceting” of search results. Faceting is an advanced search functionality that helps users pinpoint desired information when confronted with a large set of searchable data. A search result set is said to be faceted when, in addition to the primary search results, a list of categories is displayed to the user that define cross sections of the result set. These categories are called “facets”. For example, a search using the keyword “frog” against Mark Twain's letters will produce a significant number of results. The user might be interested only in the letters that contain the word “frog” and were written to Mark Twain in the year 1870. The faceted search result displays a list of facets in addition to the primary results. Two of these facets are “Letter Direction” and “Date Written” with their respective values listed under the facet name. The user can then click on facet values of interest to distill the large result set generated from the initial search into a concise, highly relevant search result. For more information on how XTF generates and manipulates faceted result sets, see Faceted Browsing in the XTF Programming Guide.
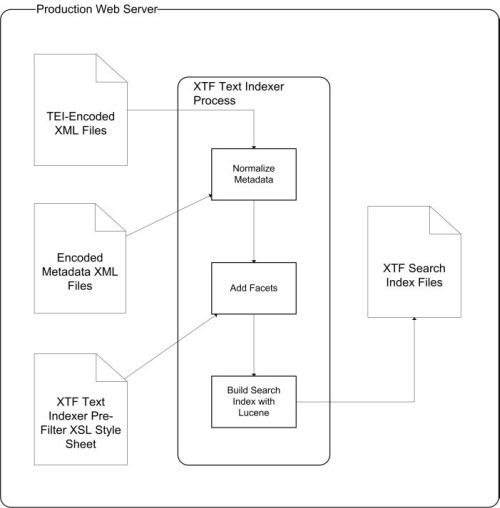
The input data indexed by MTPO consists of encoded metadata files and TEI-encoded documents. These files are transferred to the MTPO web server, where the Text Indexer runs as a one-time batch process. Thereafter, when a file or piece of metadata is modified, the affected files or data are re-transferred to the web server, and in the case of metadata, re-encoded. An incremental reindex is then run to incorporate the modified data. The indexing process produces facets from the metadata for each searchable content type on the site. The facets are generated by applying a customized preFilter XSL style sheet that lists every facet to be generated. The search index files are stored on the web server. The indexing process is shown in Figure 4.
Figure 4
VI. User Experience and Technical Implementation
For the purpose of this document, the user experience is defined as the set of functionalities implemented and exposed over the Internet by the MTPO web application. The MTPO web application is a set of interoperating server-side and client-side technologies. Functionality is invoked when a user interacts with a web page served over the Internet by the web application. Usually the interaction is in the form of an HTTP request sent to the web application by the client for processing. In response to the HTTP request, the web application performs any internal processing required to fulfill the request and then sends back the resulting web page to the client. Some functionality, however, does not require sending a request over the Internet to the web application. Instead, this functionality is implemented by JavaScript embedded directly in the web page. This JavaScript executes within the HTTP client on the user's local computer.
Primary User Functionality
The primary functionalities that define the user experience of the MTPO website are:
- Searching for objects
- Browsing for objects
- Accessing an object and its views
- Searching within an object
- Manipulating the textual apparatus of an object
- Creating personalized lists of references to content
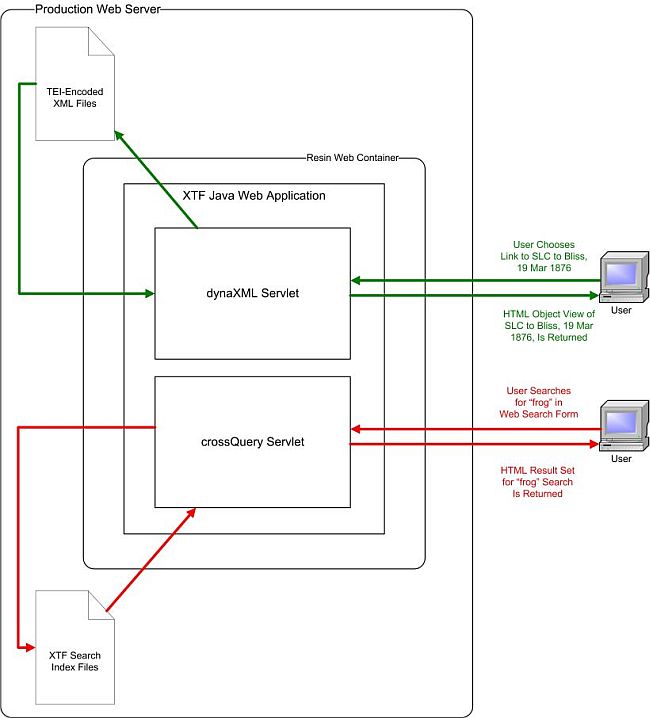
The term “object” is used to describe any discrete piece of content that is viewable on the MTPO website. Objects may include texts that Clemens intended for private or public consumption, as well as images. The user experience for search and display is shown in Figure 5.
Figure 5
Searching for Objects
Users have the ability to create simple keyword searches or more complex searches using additional constraining criteria, such as the date of publication. Although this functionality is helpful, it is not sufficient to enable users to manage the vast amount of data that is searchable on the MTPO website. For Letters, MTPO offers the addition of faceted search technology to help users effectively refine large search results based on particular areas of interest.
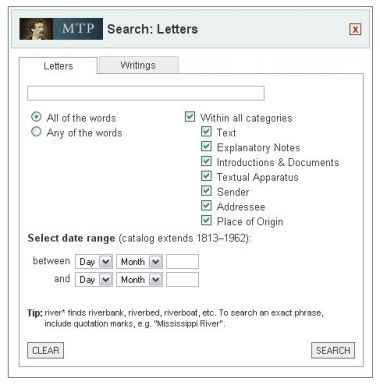
An HTML search form provides the user interface for submitting Letters search criteria. The search form is composed of separate tabs that are used to search different areas of content. A user can enter keywords in the free text field and specify additional criteria, such as a date range. Figure 6 shows the MTPO website search form.
Figure 6
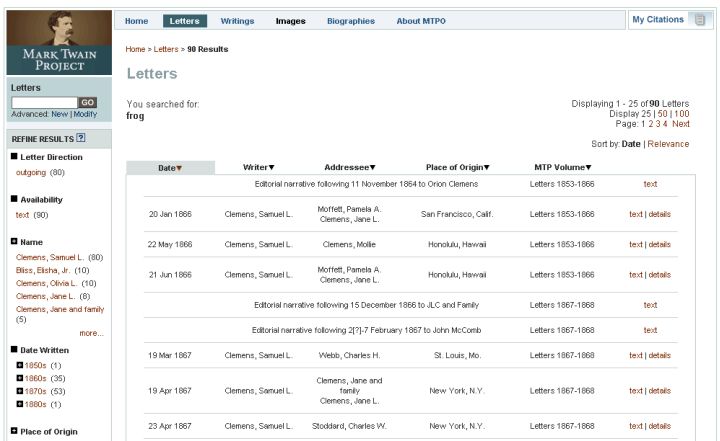
After a search is submitted, a results page is displayed that contains a list of objects matching the search criteria as well as any relevant facet value links. Figure 7 shows an example of the search results page.
Figure 7
For Writings, the current implementation allows the user to search the text of one volume at a time, using a keyword search field available only within that volume. Future development will enable the user to search across Letters and Writings content.
To implement search functionality, MTPO uses XTF, which includes a Java Web Application aRchive (WAR) that can be run on any J2EE-compliant application server or Java servlet engine.
The XTF WAR contains a number of servlets that provide generic search and display functionality. These
servlets are configurable through XSL style sheets. The locations of the XSL style sheets are contained in configuration files
with a .conf extension that correspond to the name of the servlet that the file configures. The WAR is contained in
a file called xtf.war.
The xtf.war file contains a servlet called the crossQuery servlet that implements search
functionality. This servlet exposes a web-based interface to query the search index created by the Text Indexer tool, as
described above. Once xtf.war is deployed to a servlet engine, the crossQuery servlet can display the search entry
form, accept user search criteria, process the criteria against the search index and return the results to the user as HTML.
The crossQuery servlet accepts a user's search criteria as an HTTP request and transforms the criteria into XML using an XSL style sheet called the queryParser. The XML is then processed against the search index to determine which data, if any, match the search criteria. The matching data are structured as XML and formatted into HTML by an XSL style sheet called the resultFormatter. The HTML is then sent to the user's browser for display. The crossQuery servlet also determines the relevant facets to display with the result set based on the configuration in the queryParser style sheet.
The crossQuery servlet has been specially configured for the MTPO web application by customizing the default resultFormatter and queryParser style sheets. The resultFormatter style sheet has been modified to display the relevant columns of data in the search results page for each area of content; Example 2 shows the section of the resultFormatter style sheet that defines a column header called “Addressee” for a search result containing letters.
Example 2
<th id="col_addressee">
<xsl:choose>
<xsl:when test="$sort='r-addressee'">
<div class="hi sort-tab">
<a href="{$sortURL};sort=addressee">Addressee<img src="{$icon.path}sort_arrow_up_red.gif"/></a>
</div>
</xsl:when>
<xsl:when test="$sort='addressee'">
<div class="hi sort-tab">
<a href="{$sortURL};sort=r-addressee">Addressee<img src="{$icon.path}sort_arrow_down_red.gif"/></a>
</div>
</xsl:when>
<xsl:otherwise>
<div class="sort-tab">
<a href="{$sortURL};sort=addressee">Addressee<img src="{$icon.path}sort_arrow_down.gif"/></a>
</div>
</xsl:otherwise>
</xsl:choose>
</th>
Each displayable column of the result set must be defined in the resultFormatter style sheet, along with the required HTML formatting. To display the list of records returned from a query, the crossQueryResult template must be referenced. The crossQueryResult template is used internally by the crossQuery servlet to store the results of a search. This template can be accessed from the resultFormatter style sheet in order to format the result data. For example, to iterate through the result set of a letter search and display each field value in the correct order, the XSL in Example 3 is used in resultFormatter.
Example 3
<xsl:when test="matches(meta/identifier[1],'^U')"> <td> <xsl:attribute name="class">left<xsl:if test="position()=last()"> bottom</xsl:if></xsl:attribute> <xsl:value-of select="if (meta/datePrime) then meta/datePrime else meta/date[1]"/> </td> <td> <xsl:if test="position()=last()"><xsl:attribute name="class">bottom</xsl:attribute></xsl:if> <xsl:for-each select="meta/writer-display"> <xsl:apply-templates select="."/><xsl:text disable-output-escaping="yes"> <![CDATA[<br/>]]></xsl:text> </xsl:for-each> </td> <td> <xsl:if test="position()=last()"><xsl:attribute name="class">bottom</xsl:attribute></xsl:if> <xsl:for-each select="meta/addressee"> <xsl:apply-templates select="."/><xsl:text disable-output-escaping="yes"> <![CDATA[<br/>]]></xsl:text> </xsl:for-each> </td> <td> <xsl:if test="position()=last()"><xsl:attribute name="class">bottom</xsl:attribute></xsl:if> <xsl:apply-templates select="meta/place[1]"/> </td> </xsl:when>
Browsing for Objects
Browsing the MTPO website can be accomplished using four different tools, accessible via links on the landing and results pages. These tools allow a user to refine a set of objects based on a specific facet value, to sort a set of objects by a given attribute, to move across multi-page object sets and to set the number of objects that are viewed on a single page. For letters, the user can also navigate directly to a document via the Letters Chronology, which is linked from the Letters object view (“All Letters by Date”).
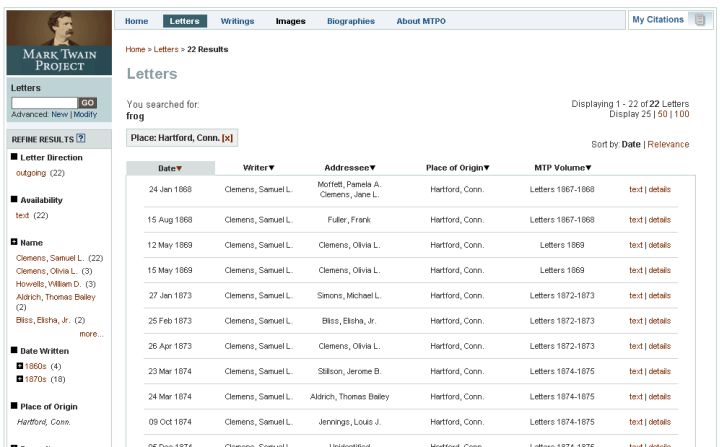
To refine a set of objects based on a facet value, the user clicks on linked facet values in the left navigation pane. In so doing, the user instructs the web application to modify the current search or browse query by adding the chosen facet value as a constraint. The user can continue to “drill down” in this way until all the facets have been exhausted. Each time a user drills down on a facet value, that value is added as a small box above the search results. These boxes display a history of each facet value the user has chosen. Removing the box for a particular facet value causes the web application to re-query the search index using the same parameters as the previous search or browse, while excluding the cancelled facet value. Thus, the user can “drill up” as well as “drill down.” Figure 8 shows a search result set for the term “frog” within the letter content that has been winnowed by the facet value “Hartford, Conn.” Note that the selected facet value is displayed above the result set as a closeable box.
Figure 8
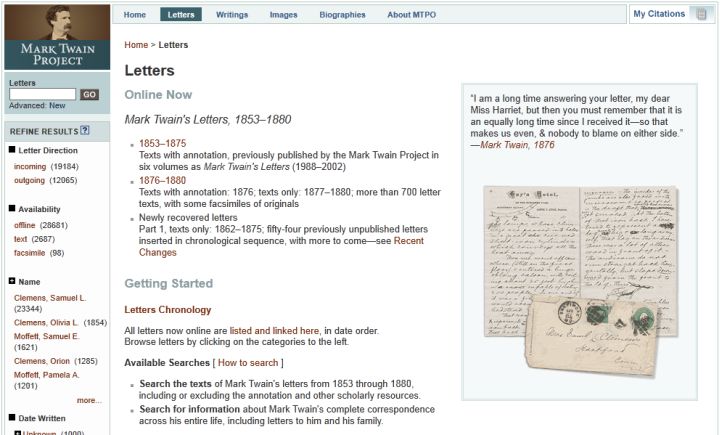
The facets can be invoked from both the search results page and the landing page. Landing pages provide an entry point from which users can explore the content of the site—accessed by clicking on the top navigation categories—without having to initiate a search first. Though different landing pages for letters, writings and biographies exist, the structure and purpose of each landing page is similar across content types. For example, the Letters landing page displays a list of all relevant facets for letter content in the left navigation pane and a static overview in the main content area. Figure 9 displays the Letters landing page.
Figure 9
From a landing page, a user can browse multiple pages of objects, sort the objects, or manipulate them in some combination of the four browsing methods previously described. A user can similarly browse from a search results page by drilling down on a facet value, sorting, paging through, setting the number of objects to display per page, or some combination thereof.
The ability to browse is a functionality of the crossQuery servlet. The crossQuery servlet accepts an HTTP parameter describing the desired browse settings and then extracts data from the search index to fulfill the request according to these settings. Note that for the sort and facet fields to be usable as browse parameters, they must be configured specifically in the Text Indexer's preFilter XSL style sheet. The crossQuery servlet uses these parameters to retrieve a properly arranged list of objects from the search index. Then the list is formatted as HTML by the resultFormatter style sheet and displayed to the user.
In order for the crossQuery servlet to meet the required browsing functionality of MTPO, its behavior has been configured using the queryParser and resultFormatter style sheets. One of the modifications made to the queryParser style sheet was to add the list of available facets. Example 4 shows a selection from the queryParser style sheet in which facets have been defined using the <facet> element.
Example 4
<facet field="facet-direction" sortGroupsBy="value">
<xsl:attribute name="select" select="'*'"/>
</facet>
<facet field="facet-availability" sortGroupsBy="totalDocs">
<xsl:attribute name="select" select="'*'"/>
</facet>
<facet field="facet-name">
<xsl:choose>
<xsl:when test="$smode='showName'">
<xsl:attribute name="sortGroupsBy" select="'value'"/>
<xsl:attribute name="select" select="'*'"/>
</xsl:when>
<xsl:otherwise>
<xsl:attribute name="sortGroupsBy" select="'totalDocs'"/>
<xsl:attribute name="select" select="'*[1-5]'"/>
</xsl:otherwise>
</xsl:choose>
</facet>
<facet field="facet-written" sortGroupsBy="value">
<xsl:choose>
<xsl:when test="$facet-written and matches($facet-written,'[0-9]+::[0-9]+::[0-9]+::[0-9]+')">
<xsl:attribute name="select" select="$facet-written"/>
</xsl:when>
<xsl:when test="$facet-written and matches($facet-written,'\*$')">
<xsl:attribute name="select" select="$facet-written"/>
</xsl:when>
<xsl:when test="$facet-written">
<xsl:attribute name="select" select="concat($facet-written,'::*')"/>
</xsl:when>
<xsl:otherwise>
<xsl:attribute name="select" select="'*'"/>
</xsl:otherwise>
</xsl:choose>
</facet>
<facet field="facet-place">
<xsl:choose>
<xsl:when test="$smode='showPlace'">
<xsl:attribute name="sortGroupsBy" select="'value'"/>
<xsl:attribute name="select" select="'*'"/>
</xsl:when>
<xsl:otherwise>
<xsl:attribute name="sortGroupsBy" select="'totalDocs'"/>
<xsl:attribute name="select" select="'*[1-5]'"/>
</xsl:otherwise>
</xsl:choose>
</facet>
<facet field="facet-repository">
<xsl:choose>
<xsl:when test="$smode='showRepository'">
<xsl:attribute name="sortGroupsBy" select="'value'"/>
<xsl:attribute name="select" select="'*'"/>
</xsl:when>
<xsl:otherwise>
<xsl:attribute name="sortGroupsBy" select="'totalDocs'"/>
<xsl:attribute name="select" select="'*[1-5]'"/>
</xsl:otherwise>
</xsl:choose>
</facet>
<facet field="facet-publication">
<xsl:choose>
<xsl:when test="$smode='showPublication'">
<xsl:attribute name="sortGroupsBy" select="'value'"/>
<xsl:attribute name="select" select="'*'"/>
</xsl:when>
<xsl:otherwise>
<xsl:attribute name="sortGroupsBy" select="'totalDocs'"/>
<xsl:attribute name="select" select="'*[1-5]'"/>
</xsl:otherwise>
</xsl:choose>
</facet>
The queryParser style sheet can also be customized to define the default number of results to display per page. This configuration can be seen in Example 5.
Example 5
<xsl:param name="docsPerPage" select="25" />
The default number of results per page is set to 25. The ability to sort the columns of search or browse results requires the
customization of the resultFormatter style sheet. Each column header is defined as a link that includes the parameter necessary
to sort the result set according to the values in the column. The HTML for the “Addressee” column header link is
shown in Example 6. Note that the browse parameter sort=addressee is part of the hyperlink.
Example 6
<a href="{$sortURL};sort=addressee">Addressee<img src="{$icon.path}sort_arrow_up_red.gif"/></a>
Accessing an Object and Its Views
After discovering an object of interest through searching or browsing, a user can view further information about it. For letters content, the “text” link yields an edited text with notes and apparatus, while “facsimile” leads to an edited text alongside manuscript facsimile images. Letters objects available in MTPO have descriptive metadata, accessible via the “details” link. Note that for many objects, only the descriptive metadata is available.
If a given object has associated facsimiles or other images, the user can click on that image to enlarge it for easier viewing. Figure 10 shows an example of an enlarged facsimile of a letter manuscript.
Figure 10

An object view can display letter texts, letter facsimiles, literary works or images. The object view displays two panes, one for the letter text and one for ancillary content. For letters, that ancillary content includes explanatory notes and textual commentary by default and, for some letters, thumbnail facsimile images. For literary works, the second pane includes explanatory notes only, whereas the textual commentary is displayed on demand in a popup window. In all cases, the text contains JavaScript-driven visual cues that are clickable and allow the user to resynchronize the view so that a given segment of text and its corresponding note appear side by side (or in the case of Textual Apparatus entries for literary works, the popup is focused on the appropriate section). Explanatory notes and their superscript note references are highlighted in blue; textual material is highlighted in yellow. More information may be found in the section Manipulating the Textual Apparatus of an Object.
Figure 11 shows an example of a letter object view.
Figure 11
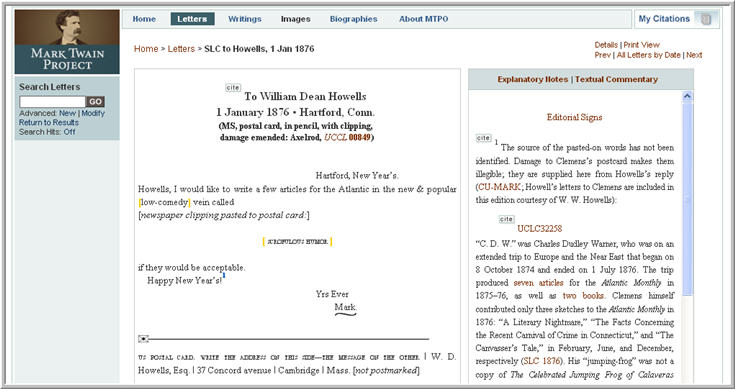
The object view for letter facsimiles includes only the text of the letter, not the notes and apparatus, in order to allow room for thumbnail images of the facsimile scans. These images appear to the right of the text pane. Selecting an image opens a lightbox popup that a user can resize or position alongside the edited text: click once to view the image at the maximum available zoom, click and hold to reposition it, and click once more to close the lightbox. To return to the regular object view for letters, select the “Text” link in the browser's upper right corner. Figure 12 shows an example of the letter facsimile view.
Figure 12
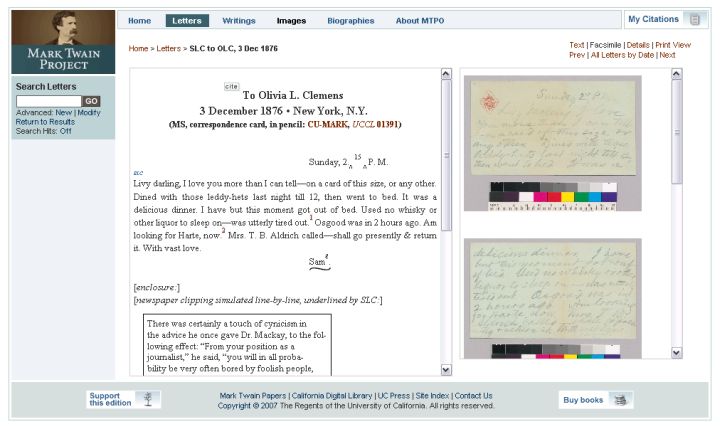
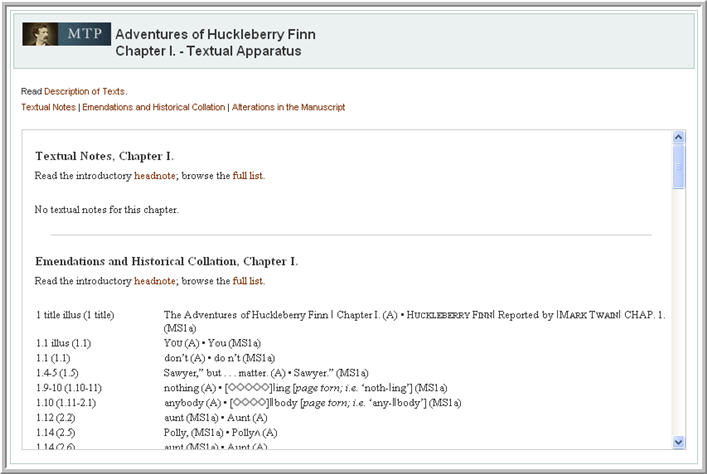
Figure 13 shows an example of a literary work object view.
Figure 13
Manipulating the Textual Apparatus of an Object
The textual apparatus of a work allows a user to see a report of the evidence and editorial decisions from which the critical text has been established. Within the printed versions of the Mark Twain Project's critical editions, the textual apparatus is included after the literary work, at the end of the volume. Sections for emendations, historical collations, authorial alterations and textual notes provide detailed lists of apparatus entries. The entries reference segments of text using page and line number cues. Readers who consult the textual apparatus within the print editions typically find themselves alternating between the main text and an associated apparatus entry near the back of the book.
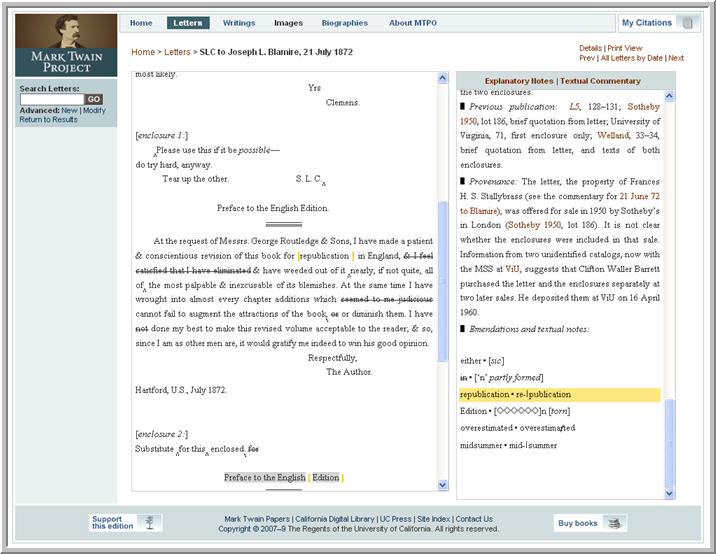
Moving the textual apparatus to the web enables a dramatic simplification of this task of consulting the textual apparatus alongside the text. The common web practice of using hyperlinks to move between pages of related data serves as the basis of the navigation model developed for the textual apparatus. Within an MTPO object view for letter-related content, the critical text and the apparatus entries for the text are displayed in adjacent text panes. When a user selects a segment of critical text that is referenced by an apparatus entry, JavaScript is invoked that highlights the apparatus entry and moves it to the middle of the note pane, on the right. Thus the user has a single view of the apparatus entry and referenced critical text, both of which are highlighted. This behavior works both ways. If a user selects an apparatus entry in the apparatus text pane, then the square brackets surrounding that referenced text become highlighted highlighted and the focus is brought to the center of the main text pane containing the work or letter. Each type of apparatus entry is highlighted in a different color. Rendering complicated highlighting schemes was greatly simplified by using CSS to define a range of styles that could be applied to different types of apparatus entries. Figure 14 shows an example of a letter object view after the emendation “republication” has been selected. Note that two levels of nested highlights have been defined to represent overlapping apparatus entries.
Figure 14
The textual apparatus functionality is implemented via XTF, TEI encoding, Cascading Style Sheets (CSS) and JavaScript. The TEI
encoding of content is essential to the creation of the online textual apparatus functionality. Every lemma is encoded using TEI
in such a way that it can be logically connected to its apparatus entry. The <anchor/> tag marks the start of
the lemma text for each apparatus entry. Example 7 displays the structure of an emendation within MTPO's TEI-XML.
Example 7
<anchor xml:id="id0018"/>stocked<app xml:id="a00003" from="id0018">
<lem>stocked</lem>
<rdg>
<note xml:id="id0020" place="inline" resp="MTP" type="ed">sic</note>
</rdg>
</app>
An apparatus entry occurs within the <app> element and includes both the textual lemma and its reading. In Example 7, the reading is simply an editorial note, “[sic]”. MTPO's CSS classes have been designed to render as well as to highlight the apparatus entry. Within this tag the details of the apparatus entry are given, including the lemma and the emended reading or editorial note. Example 8 shows a CSS snippet that defines the way text is bracketed for an apparatus entry.
Example 8
#object #content-primary .bracket-apparatus {
color: #FFCC00;
font-weight: bold;
}
The XTF dynaXML servlet's docFormatter XSL style sheet associates the CSS display class in Example 8 with the apparatus
entry bounded by <anchor/> and <app> tags in Example 7. Example 9 shows a section of the
utils.js support code that enables highlighting an apparatus entry.
Example 9
function hiliteNote(noteID) {
var note = document.getElementById(noteID);
if (note) {
var noteClass = getClassValue(note, 0)
if (noteClass == "altnote") {
note.className = "altnote-hi";
} else if (noteClass == "appnote") {
note.className = "appnote-hi";
}
}
}
The JavaScript function checks whether the “note” is an alteration or a general apparatus entry, then assigns the appropriate CSS class. The class facilitates additional JavaScript functions. For example, when a user clicks on the apparatus entry's lemma bracket in the object view, JavaScript code scrolls the contents of the note pane so that the relevant apparatus entry is centered and highlighted. All notes and apparatus entries in the note pane are clickable via JavaScript. Clicking on one repositions the associated note reference or lemma so that it is visible in the text pane.
The apparatus for literary works is structured and manipulated in a similar way; however, the textual apparatus is presented in a secondary popup window, not (as in letters) in the right pane following the explanatory notes. Figure 15 shows the textual apparatus for a literary work as it appears in the popup.
Figure 15
Editorial Signs and Symbols
Maintaining print edition standards in the online edition required overcoming another set of challenges. Foremost among these challenges was finding web-based equivalents for special characters and symbols used in the print editions. The problem of graphic groups illustrates this challenge. A graphic group is defined in MTPO's internal style guide as follows:
Transcriptions of all varieties—letters, notebooks, working notes—may contain paragraphs or lines united by a visual element. This visual element may be a brace that groups several lines of text, or it may be a large “X” overlaid on a paragraph. Paragraphs or lines joined by a visual element are called “graphic groups”. Graphic groups can contain paragraphs or lines. In addition, graphic groups may contain font shifts, editorial symbols, special characters, and quotations.
Figure 16 shows an example of a graphic group, which is the right brace above the salutation spanning two lines of text.
Figure 16
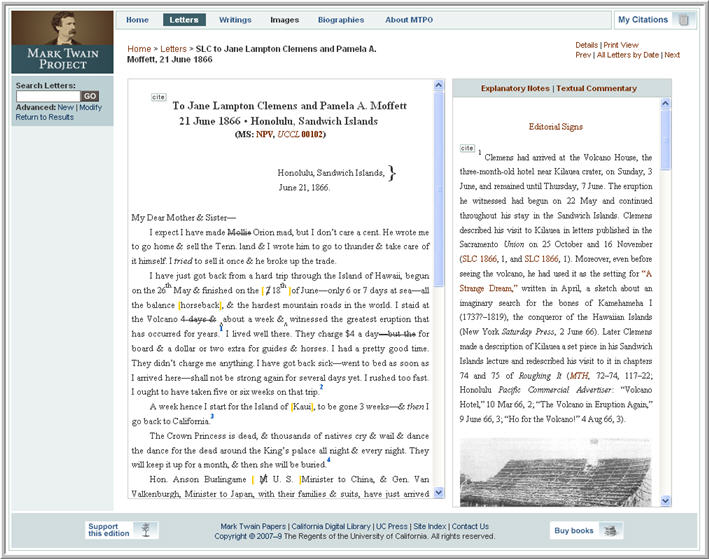
Standard HTML and CSS2 do not offer an obvious solution for rendering graphic groups. Many different types of graphic groups exist in Mark Twain's letters and writings. It was important to develop a generic solution for rendering graphic groups in order to accommodate unknown graphic groups that might occur in future editions.
The graphic group issue was solved by innovating within the TEI schema to create a new element called
<graphicGroup>. Example 10 shows the graphicGroup definition in the extended DTD.
Example 10
<!ELEMENT graphicGroup %om.RO; ( ab | argument | bibl | biblFull | biblStruc | byline | camera | caption | castList | cit | closer | dateline | docAuthor | docDate | epigraph | eTree | graph | graphicGroup | head | l | label | letterhead | lg | list | listBibl | move | opener | p | q | quote | salute | signed | sound | sp | stage | table | tech | text | trailer | tree | view | witDetail | witList)+ > <!ATTLIST graphicGroup location (right | left | top | bottom | overlay) #REQUIRED align (inline | margin) #REQUIRED orientation (horizontal | vertical | diagonal) #REQUIRED number CDATA #REQUIRED rend (slash | x | circle | box | squiggle | brace) #REQUIRED >
The <graphicGroup> element is composed of a list of attributes that represent different types of graphic
groups identified in the critical editions. For example, the brace in Figure 15 is represented by an @rend
attribute value of brace. Example 11 shows the TEI-encoded graphic group rendered in Figure 15.
Example 11
<graphicGroup location="right" align="inline" orientation="vertical" number="1" rend="brace"> <dateline rend="indentdateline">Honolulu, Sandwich Islands, <lb/> <space extent="20"/>June 21, 1866.</dateline> </graphicGroup>
When the writing containing this graphic group is requested from the site, the TEI-encoded <graphicGroup>
element is translated into a CSS class that creates a brace spanning two lines. The mapping between
<graphicGroup> @rend values and CSS classes is maintained in the XSL style sheet that performs
the XML-to-HTML translation for object views. This solution provides an extensible way of dealing with new graphic groups. If a
new graphic group is required in future editions, then three simple changes can be made to accommodate it. First, the TEI DTD
can be modified to add another value to the @rend attribute. Second, a new CSS class can be defined to represent
the display of the new graphic group. Finally, the XSL style sheet can be updated to map the new XML attribute value to the new
CSS class. This solution maintains the editorial integrity of the critical edition's digital version.
Some graphic groups fall well beyond what HTML and CSS can support at present. The centuries-old art of print typography is not
yet matched evenly by the web. For example, Clemens's freehand cancellation lines are represented in the printed UC Press
editions by an overlay, lines atop typeset text. Though these unique instances may be encoded by
<graphicGroup>, as a temporary measure they are rendered by an image of the printed representation and
accompanied by an editorial note.
Creating Personalized Lists of References to Content
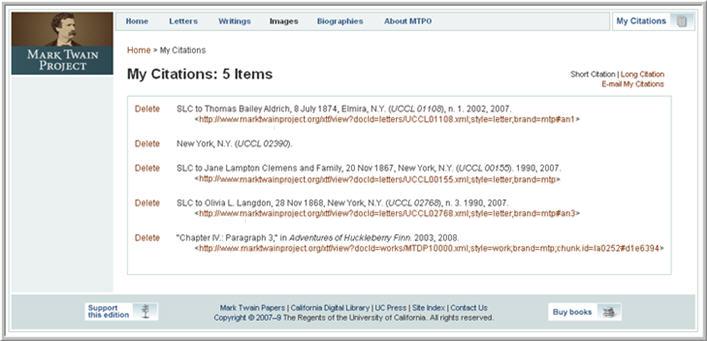
Users can build personalized lists of content references on the MTPO website. These references can be displayed in short or long form, and the lists can be sent via email to the user or other interested parties. The page that collects the user's references is called My Citations and can be invoked from the home page as well as all search, browse and object view pages. A user can add references to My Citations in two ways. From search and browse pages, click on “Details” to view a lightbox record for any text or metadata object, then click on the “Add to My Citations” link. Within the object view there is a clickable image next to each citable piece of content, as shown in Figure 17. The “Details” lightbox is also available from object views.
Figure 17

The My Citations page is specific to the current user and the current browser session. Note that My Citations functionality does not persist between user sessions: if the browser is closed after a personalized list of citations has been collected, the list is lost.
To retain a copy of the references collected during a session, the user can click on the “Email My Citations” link from the My Citations page. In the lightbox that appears, the user can type one or more email addresses, separated by a comma and a space, then click on the “Submit” button. The recipient(s) will receive an email that gives the long form of each citation in the list, with links to each content item on the MTPO website. Figure 18 shows an example of the My Citations page.
Figure 18
The My Citations functionality is based on three technologies: Asynchronous JavaScript and XML (AJAX), J2EE server sessions, and XSLT Java extensions.
When a user clicks a citation link, AJAX code is executed that calls the crossQuery servlet remotely in the XTF application.
The call takes the form of an HTTP request that passes a parameter called smode to the server. The URL contains
contains a semicolon-delimited list of values, including the smode parameter with a value of "addToBag", the unique
identifier of the object the user would like to add to My Citations and a marker value (addToBag) indicating which
functionality is requested. When the crossQuery servlet is called, it executes the resultFormatter style sheet, which checks to
see if the smode parameter exists and whether it matches one of three different values related to My Citations functionality:
addToBag, removeFromBag and showBag. Depending on the value of the functionality marker,
the resultFormatter style sheet calls another template according to the marker. For example, a request sent with the parameter
addToBag invokes a template called addToBag that uses an XSLT Java extension supplied by XTF in order
to manipulate the user's HTTP session.
After the user's list of references has been updated, the crossQuery servlet sends a response back to the client in the
form of an HTML snippet, which is displayed by the browser. Under normal circumstances the HTML snippet is a message indicating
that the content has been successfully added to the user's list, such as the message text “Added.” Content
items can be removed from the list by accessing the My Citations page and clicking the “Delete” link next to a
previously added item. As a result, the URL parameters are passed to the crossQuery servlet with the item's unique
identifier and a marker value of removeFromBag, which in turn calls the removeFromBag XSL template.
When a user visits My Citations, the crossQuery servlet is called with a functionality marker of showBag. The
showBag XSL template is subsequently called, which reads all the values of the bag variable in the HTTP session so
that they can be displayed on the web page when the resultFormatter style sheet is invoked.
Collecting Citations
Users can add any citable content (as defined by the MTPO editors) to the My Citations page, as described above in Creating Personalized Lists of References to Content. Two formats exist for citations, a short form and a long form. The short form is meant to serve as a quick reference; the long form is based on the reference-list styles given in The Chicago Manual of Style, fifteenth edition (2003). For textual entries, both citation forms include a durable web link that helps users to return to the corresponding texts on the MTPO website. Example 12 shows the two forms for a citation of an explanatory note in a letter.
Example 12
Short Form:
SLC to Olivia L. Langdon and Charles J. Langdon, 21 and 23 Dec 1868, Detroit, Mich.
(UCCL 00207), n. 3. 1990, 2007.
<http://www.marktwainproject.org/xtf/view?docId=letters/UCCL00207.xml;
style=letter;brand=mtp#an3>
Long Form:
“SLC to Olivia L. Langdon and Charles J. Langdon, 21 and 23 Dec 1868, Detroit,
Mich. (UCCL 00207),” n. 3. In Mark Twain's Letters, 1867–1868. Edited by Harriet Elinor
Smith, Richard Bucci, and Lin Salamo. Mark Twain Project Online. Berkeley, Los Angeles, London: University of California Press.
1990, 2007.
<http://www.marktwainproject.org/xtf/view?docId=letters/UCCL00207.xml;style=letter;brand=mtp#an3>, accessed
2007-09-01.
By default the short form is displayed on the My Citations page. Click on the Short Citation and Long Citation links to format the citation accordingly.
Archiving and Preservation
Shortly after MTPO's initial release, MTPO began archiving its encoded metadata, TEI documents, and images in the CDL's Merritt service, formerly called Digital Preservation Repository (DPR). Merritt is a set of services available to University of California (UC) libraries for the preservation, management, and controlled dissemination of digital objects that support research, teaching, and learning. Archiving in Merritt ensures that the digital objects and metadata displayed on the MTPO website are secured for future use. The process hinges upon the submission of METS objects, which Merritt uses to ingest the digital objects that they describe. The METS data is created by a process similar to that which creates METS records for the search index. For more information about the latter process, see Metadata Encoding, above.